

The Apropos show with Zach Tellman was a success (despite a technical hiccup; it wouldn’t really be Apropos without hiccups). And next week we have Alex Miller as a guest. Please join us on YouTube. You can ask us questions in the chat.
And let’s not forget Grokking Simplicity, my book for beginners to functional programming. Please check it out or recommend it to a friend. You can also get it from Manning.
How to make each feature take less code
Last week I lofted the dream of being able to write the same features with less code. Let’s talk about some practical ways of achieving this.
Reusable abstractions
The first way is the normal, humdrum way: you build abstractions that are used multiple times, so you get more features out of every line of code. This has been the pipe dream of the industry for a long time. I want to argue that we have achieved this, but in an unexpected way.
Let’s say your company write software to schedule the delivery of king cakes (it is Mardi Gras season). As the number of features grows, the programmers start to notice certain regularities. For instance, they have logic for doing date math all over the codebase. Each place has to handle rolling a date over to the next day when you go past midnight. So they start to gather those bits of code into a central place. They see that there is much repetition and irregularity. They redesign the date math to be a library with clean abstractions. And the code is smaller for it.
The smallness comes from:
Identifying important domain concepts (seen as repeated routines)
Writing them at the right level of generality
Reusing them throughout the code
But what happens when you go to write the next feature? You obviously use the date library you just wrote. But is there more? Does each new feature make the next one take less code? In my experience, no. Even if you’re very diligent about identifying reuse, there seems to be a limit to how far you can take this. Buy why?
Is it because there just isn’t that much repetition? Is it that even if you squeeze out all of the repeated ideas, there’s still so much special casing? I tend to believe that we don’t take it far enough. I only have some anecdotes about what it would really look like to wring out all of the general ideas (mostly through rewrites). Practically, it’s often not possible to do a rewrite. And the repeated concepts aren’t so clear in the code. And the system is already too big to hold in your head to see how things might work. Finding those new abstractions is a research project. We resign ourselves to modularize only to contain the mess.
But I promised that I’d argue that we have achieved this kind of widespread reuse. Well, we have, but not in a way that makes each feature less costly than the last. We have massive reuse in our software today. We build software by piecing together existing libraries—usually open source. Those libraries are reused all over the world, in many different contexts. We rarely write our own data structures—they come with the standard library. Or our own HTTP libraries. Or the UI widgets we use. It’s all reused code, but at a global scale.
Before I move onto the next section, I’d like to plug a paper:, Lisp: A language for stratified design. It goes into detail about how abstraction can improve your design. I did it on my podcast, but there’s also something missing from the paper.
Just for completeness, here are the relevant highlights:
our designs need to be more general than the problem they are solving
identifying the right domain concepts is crucial
layering function definitions allows us to express the specific in terms of the general
the closure property explodes the number of possible combinations through nesting
metalinguistic abstraction lets you switch to a new paradigm
It’s all about leverage. Each bit of leverage is a small amount of code, but it adds disproportionate power. Each layer adds leverage, building on the leverage from below. The top layer has a huge amount of power from the combination of the tiny bits of code it sits atop.
Driving the exponential
While writing my essay last week, I thought of another way to achieve the same thing, even if it is theoretical. Here’s a graph I showed last week of a dream for exponential feature growth. That is, more features per line of code:
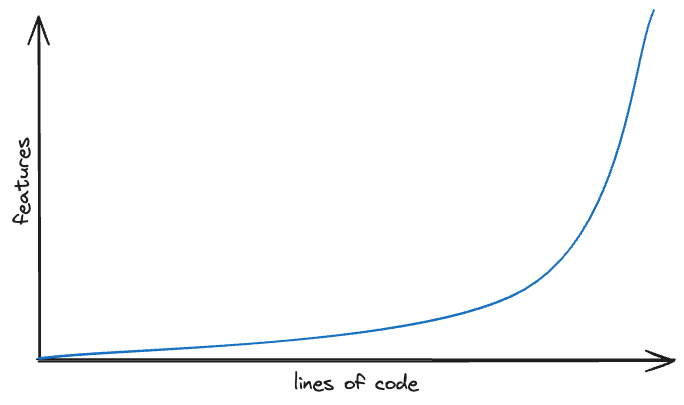
In modern startups, they often look for exponential growth. If it’s not one of those lucky products that gets adoption with no effort, the road to exponential growth is slow and a slog.
If you ask anyone who’s been through it, they would say that their exponential curve is a stack of linear curves, each with a higher slope. Each new line is a discovery: An ad campaign that drives traffic. A new offer on the website. A new channel that brings new customers
Last week, I scoffed at the idea of a new language feature helping us out. All it can do is improve the slope. And it’s true: It only improves the slope once. What we need is a way to continually improve the slope. We need a way for new code we write to make the next line of code more powerful.

This sounds like an argument for continuous and aggressive software design. But it rarely happens. Why?
My hunch is the same explanation for why we Aristotelian physics lasted for thousands of years before a handful of scientists (Galileo, Newton, etc.) found a better abstraction within a lifetime. It is that it’s hundreds of times harder to design software this way (to get more and more out of less and less code) than it is to get the next feature working without design. Galileo spent years developing equipment and experimenting with balls of different weights and sizes. Newton toiled over scientific texts, refined his scientific method, and invented a new kind of math just to explain what he was seeing. It’s laborious and requires the luck of insight. As much as Newton mastered alchemy, he did not invent chemistry.
When you’re working in a well designed system that is at the right-hand side of this graph, it feels amazing. But the work to get there is enormous. In the lifecycle of businesses, where time is money, you’d much rather work on the red graph, with its high slope, for as long as possible, switching to the orange graph after you’ve secured marketshare and cashflow.
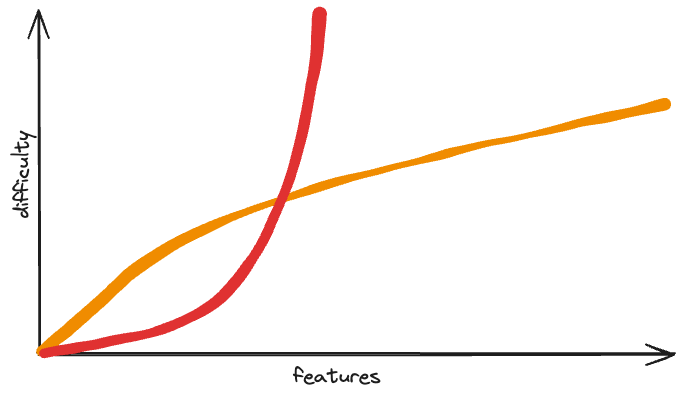
But we do see that big companies, after they make billions, do reinvest to switch over to the orange curve. Facebook experiments with their own PHP compiler, new GUI frameworks, and other paradigms. Google writes their own languages, invents distributed computing frameworks, and builds vast libraries of high-generality code. Once they make it big, they want to switch curves by rebuilding the lower layers. But it’s research projects. They have a low probability of success but a high payoff if they do. Most of us don’t have the luxury of that kind of work. We’re raking muck and piling it higher. It’s the economically correct thing to do.
Does it ever make sense to design before you’ve made it big? I think so. Every team has a maximum capacity of difficulty. As you approach that capacity, you slow down, even if the slope of the curve isn’t that high. Before you hit that capacity, you’ve got to do everything you can to bring the difficulty down. You can add tooling to flatten the curve. Or you can do some design work to lower the exponent. You’ve got to convince the company, using the idea of risk to the feature and revenue milestones, to get that curve under control. The biggest difficulty is that you have to go from feature-building mode to a more reflective, scientific curiosity mode, to look for the abstractions that will help.
Last week I got a feature request from our member services folks that I thought would be really hard to implement, and would require a lot of custom code.
This week, I started to dig into the code and found that the three pieces I needed already existed -- in two different combinations already! -- but they weren't organized for reuse, so it took a bit of refactoring first, moving code from individual apps into libraries, and then the new feature was a simple matter of added a pipelilne of three calls (to existing code, that just needed moving).
So, yeah, I think the core of what you're saying is _possible_ but not common within application code -- but we see it a lot with more generic, non-application code.
Oh, and the Alex episode was great!