
How does dev tooling help?
A made-up model of dev tooling improvement

The Apropos folks (well, at least 3 of us) are back on YouTube! And we’re figuring out the tech. Subscribe to the channel to be notified before we go live. We broadcast this Tuesday with guest Zach Tellman!
And let’s not forget Grokking Simplicity, my book for beginners to functional programming. Please check it out or recommend it to a friend. You can also get it from Manning.
How does dev tooling help?
There’s something about dev tooling that rubs me the wrong way. Don’t get me wrong. I’m all for linting, type checking, static analysis, etc. It definitely helps. But it’s always kind of sad, like admitting defeat. I wanted to explore this mixed feeling. Here’s what I came up with.
Why do we like dev tooling? Why does it help us? What people say it’s for is to make working with large codebases easier. Sure, it helps small codebases too. But the gain is bigger for large codebases. Here’s a graph showing the lines of code vs the difficulty of working in it.

This hand-drawn, completely made-up graph represents my understanding of the relationship between lines of code and the difficulty of working in the code. The more code, the more difficult. But the relationship is more than linear. Is it exponential? Who knows? But at some point you hit a wall where the difficulty goes up. This matches my experience.
Notice that there are no units or scale. I didn’t say what language, either. This is a kind of universal graph. Your current codebase falls somewhere on this curve.

I’m going to call this red curve the baseline. What happens if we leave the codebase the same, but we add a linter? It “flattens the curve”, making the same size codebase easier to work with.
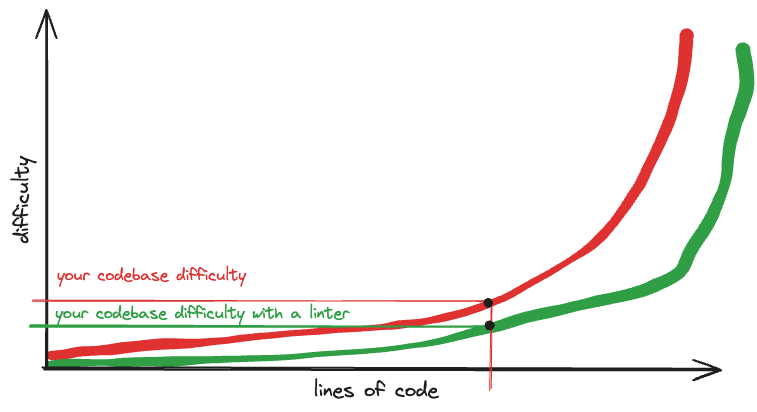
A linter will help you find errors and avoid new ones. It makes working with the same code easier. The same happens when we add type checking. Or when we add jump to definition. Or when we add regression tests. Everything flattens the curve a little more. Tests also add to the codebase, so they’d better flatten it more than they cost or they’re not worth it.
You’ll notice also that the improvement that you see is bigger with bigger codebases.
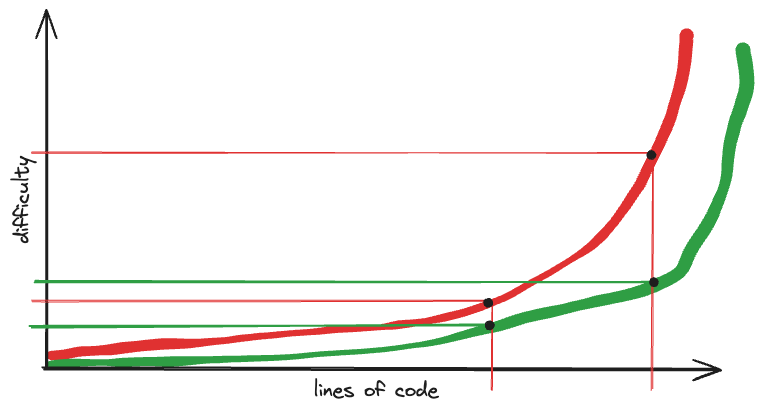
All the same, eventually you run out of tools. You’ve turned on all the linters and all the type systems you can find. You’ve got regression tests for everything. Your whole system is under 24/7 watch by robots of all kinds. There’s no more flattening to be had. Congratulations, you’re at a new baseline.

Yes, the curve is flatter, but because it was easier, you grew your codebase. You didn’t just use the decreased difficulty to take a rest. You kept adding features like the business wanted. And now you’re right back where you started—except with more code and you’re dependent on robots. I’m not saying it’s a bad thing, mind you. It’s just a fact. But there are no more bots to help.
There’s something like the Peltzman Effect going on. That’s the phenomenon that safety features on cars just make people drive more dangerously. The net effect is still positive—there are fewer driver and passenger fatalities with seatbelts than without. Similarly, we code more because we’ve got help. We’ve got more features because the tools let us handle more.
The model also explains another phenomenon. We also feel a kind of natural slowdown as we get closer to the steep part of the curve. At some point, we cannot add more code without things being too difficult to handle. If we’re under pressure to keep adding features, there will be backpressure from the codebase. We reach an equilibrium, which results in a certain velocity of added code. That velocity will approach zero as code is added.
It’s a good time now to remind everyone that this is a hand-drawn, made-up model. I have no real measurements. It’s just a show. But, if the model is correct, we know what happens. And I do believe this model—based on personal experience.
And I think this is why I’ve always felt uneasy when people get excited about this kind of dev tooling. Yes, it helps. But it only delays the inevitable.
What my heart has always dreamed of is a way to build the same system with less code—instead of how to make it easier to write more code. Is there some way to move to the left while maintaining the same features?

That’s a way to make it easier without changing the curve. This is what I imagine happens when you switch from assembly to a higher-level language. You can write the same software with less code. But what if we could change the curve?
Let’s imagine for a second that there is a linear relationship between the lines of code and the number of features.

What I’d love to have is a way to make that super-linear:

Because what we really want is more features. So if we can do that with less code, all the better. Let’s assume for discussion that the code vs difficulty and the code vs features graphs are both exponential, that is:
(where f is number of features, l is the lines of code, d is the difficulty, and that symbol means “proportional to”). If you solve for l and put it into the equation, you get:
If n > m, then we are in business! We can then graph features vs difficulty like this:

That is, the more features we have, the easier it is to make new features—the features compound to make the next feature that much easier. As we add features, yes, the difficulty goes up, but it goes up less each time. This might be a pipe dream, but it has been there a long time, and it’s mine.
And now that I mention it, it’s why I scoff (to myself) at new languages and new language features. They’re often just changing the slope of the lines-of-code vs features graph. They don’t improve the exponent.
I just want to end this with one more thought. Let’s draw the equivalent graph on here for where we started:

Now, of course these are just made-up, hand-drawn graphs. They’re not to any scale, but you can get the idea of a major tradeoff. The orange curve has a high slope at the beginning while the red curve has a high slope at the end. Number of features is roughly the amount of time you’ve spent on the project, which means orange projects will be harder at the beginning. That’s good to know. But, likewise, red projects will be harder at the end. But, of course, you could squash both of them with dev tools, and get intersections at totally different points.
In the next issue, I’d like to explore some ways we can achieve better curves for feature difficulty. Is it possible to make each new feature take less code than the last?