
Bad data models lead to code complexity
Extra ifs are the cost of poor data models

Our last Apropos was with Alex Engelberg. Check it out. Our next episode is with Sean Corfield on March 11 (Paula had to cancel). Please watch us live so you can ask questions.
Have you seen Grokking Simplicity, my book for beginners to functional programming? Please check it out or recommend it to a friend. You can also get it from Manning. Use coupon code TSSIMPLICITY for 50% off.
Bad data models lead to code complexity
There I was, staring at a complex, nested if statement with hard-to-follow logic in each condition. What’s worse, similar logic was repeated in several places in the codebase. That was when I realized how much complexity a bad data model can cause.
An example of a bad domain model
The domain was simple. I’ll describe a similar one that is an easier example so I don’t have to explain the whole domain. Imagine a content management system for a magazine. Articles go through several stages as they are prepared for publication:
Drafting
Editing
Approval
Publication
We modeled it with several Maybe<DateTime> type. As we finished a stage, we added the time. If the time didn’t exist, it meant that we had not finished that stage yet.
type Document = {
drafted? : Date;
edited? : Date;
approved? : Date;
published?: Date;
};This worked for a while, but eventually we found problems.
The first problem was that our logic was complicated and duplicated. If we wanted to know if something was in the approval stage, we had logic like this:
if(document.drafted && document.edited && !document.approved)The second problem was that as we increased the number of documents in the database, with many releases to our software (often with bugs), we eventually got data that had impossible states. For instance, it was edited without being drafted:
{
drafted: null,
edited: new Date("2010-01-02")
}How could this happen? Well, despite our checks, something slipped through. Maybe it was a bug in a prior release. Maybe it was user error. Whatever the case, it existed, and our code needed to make sense of it. That meant more if statements.
This is a bad data model. I mean that in an objective way. We can actually measure how bad it is. We can count the number of states in the domain and the number of states in the model, and see how far off they are from each other. Here is the timeline of a document workflow:
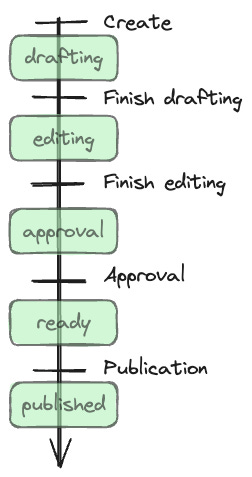
The horizontal lines represent events that divide the timeline into sections. Each section is a distinct state that the document can be in. We see clearly that there are five states a document can be in in this domain.
Our model is different. It contains for optional values, where the presence of the value is meaningful. The date is also meaningful, but in a different way. I’m going to ignore it for this analysis, even though it also could present difficulties such as if a document is published before it is drafted. We’ll just look at the presence or absence of the value.
In that situation, there are four values with two options each (present/absent), which is 2^4 = 16. So our data can represent 16 states. That means that 11 of our states are redundant, ambiguous, or invalid, because we only needed 5.
That sucks. Those unneeded states caused a lot of code complexity because our code had to map them to the domain concept. It had to deal with the ambiguity of the situation. That was the second problem I talked about (finding impossible data in the database). We could have seen this coming with some simple math.
The first problem was still there. Remember, the first problem was about the complex, duplicated logic we found everywhere. It wasn’t really because there were ambiguous states. It was more that what we stored didn’t correspond well to what we needed.
Remember, we were storing the time that we crossed each of the horizontal lines. But what we wanted to know was which green box we were in. We had to write compound conditionals to convert the lines into boxes.
Adapting the existing data model to a better one
Luckily, we can adapt this model and solve both problems with in one stroke. Remember, domain modeling is about mapping. So let’s create a function that maps the data model we have to the data model we wish we had:
function documentStatus(document) {
if(document.published) return "published";
if(document.approved) return "ready";
if(document.edited) return "approval";
if(document.drafted) return "editing";
else return "drafting";
}We did double-check to make sure that this does correctly map the ambiguous states to the correct states. Luckily, it was simple. We could imagine it being much more complex than this. For instance, we might have a check somewhere in the code that a document with a published date but no content is actually in the drafting stage. I have a hunch that this is where the really hairy complexity comes from—different behavior in different places in the codebase because of inconsistent logic. Either way, having a single place that defines the mapping to our desired model is a good thing. The biggest trouble with it is making sure to use it consistently.
We could then use the human-readable string representing the status in place of a bunch of booleans anded together:
if(documentStatus(document) === "approval")instead of:
if(document.drafted && document.edited && !document.approved)Here are the things we achieved:
Centralized the logic for determining the status
Eliminated inconsistencies in status logic across the codebase
Made status checks more human-readable
Eliminated complex conditional logic
I’d say it was a major win.
Is this a major win? Or a waste of time?
Even still, I have encountered people who think this is a waste of time. To put a fine point on it, this change was both small (in the number of lines of code it saved) and extensive (in the number of lines of code and the number of files it touched). Further, it was risky. Changing so many lines of working code could introduce bugs we couldn’t anticipate. In short, it’s high risk and it doesn’t eliminate much complexity.
When I ask them about where code complexity comes from, they say it’s from other sources—mainly business logic, user requirements, and system interactions. Bad domain models do introduce complexity, but it’s a rounding error compared to those sources.
My response is always the same: Those sources of complexity can be modeled, too. Nesting if statements is one simple tool we have to address a corner case. I’ve done it myself thousands of times. It’s extremely useful when I don’t have the time to fully understand what is happening in the codebase. Surgically adding an if where I’m certain it will be useful is a versatile tool.
But nesting ifs is a tool that breeds more complexity. The next time I or someone else needs to handle a new case, it becomes that much harder to understand, so that much more likely that we’ll add yet another if.
Modeling is the only way to rein in complexity
Look, I’m getting deep into the weeds here, and I need to bring this thread back to my intended point: There’s no way to clean up those ifs without understanding the domain. All a domain model is is an understanding of the domain expressed in code. When you express it in code, its an understand that is available to anyone who cares to read it. Domain modeling is software design. Trying to eliminate complexity without modeling is a fool’s errand. Domain modeling is a necessary skill for designing software. So we might as well get good at it.
When we talk about modeling business logic, often people hear “oversimplifying”. That is not what I’m talking about at all. Domain modeling means embracing the complexity, but identifying the structure of it, then writing that structure down in useful code. Maybe I’m preaching to the choir, so I’ll just leave it at that. If you’ve got an understanding, you can write it down. I also hope to show that there are objective measures of data model quality in my upcoming book. Modeling is a skill, and you can get better at it.
Conclusion
Code complexity is a major cost of software development. Bad data models add significantly to code complexity—when models don’t correspond to the domain, we require extra code to handle the redundant and missing cases. Cleaning up the data model can significantly contribute to reducing complexity. Even if you think that data models aren’t a major source of complexity, the sources of complexity can also be modeled. Chances are, the current models of things like business logic, user requirements, and system interactions are poor models. They’re adding way more complexity than they actually need. You can clean those up, too.
I hope to bring this awareness of poor models to the industry. Currently we’re stuck thinking about code in isolation instead of how it relates to the domain. I’d like to help fix that, which is why it’s a major theme of my book. I don’t want domain modeling to be just another abstract skill. Instead, it’s fundamental to software design. The more I research it, the more I see that it’s the real key to explaining a lot of software design advice.
Do you have any interesting stories involving domain modeling? How do you apply domain modeling in your work?
This is great stuff. At work, over time, we started with a Boolean flag for one aspect of a member profile, and later had another slightly related Boolean flag for a different aspect of a member profile, then we realized we needed to synthesize a new status from the two Booleans -- a three-state status. And of course now we have four possible states where only three are valid.
We did exactly what you advocate here: we introduced functions to "get" and "set" the status and replaced references to the old fields with calls to this status function. Later we modified the "getter" to heal the profiles that were in that fourth, invalid state -- because of course that happened to us, despite it "not being possible". We still have the two underlying Boolean columns in the database -- we didn't feel it was worth the time and effort to add a new status column and migrate the old flags into that...
Our database schema dates back to 2012 at this point, and it's been heavily modified over time as business requirements have changed, so it has a trail of now-incorrectly named and/or unused columns -- which we paper over in the code, to maintain the accuracy of the domain model's evolution.
For example: in our legacy (pre-2012) system, members could "wink" at each. Then business renamed that action to "flirt" (with a slightly different set of rules), then it got changed to "like" with a reciprocal "connection" state, and then the rules changed to withhold delivery of likes until the initiating profile was approved, etc. We did a database migration from flirt to the initial version of like, and then built functions to support the domain for everything else.
That was part of my talk I presented on a couple of conferences. I showed the connection between removing "not-reflecting-reality" states in the model of the reality and simplicity in reactive programming. At the end if we can remove such states from the program, that program would have less errors and less complexity. :)
In reactive programming it's even more important to do that early (e.g. at response from API)